
The Bee team has been working hard on measuring and identifying key problems in the swarm DHT these last few months. As promised in a previous blog post, we’ve finally pulled the trigger with v1.3.0 on a change that ostracises nodes without a stable blockchain connection from the network. This was just the herald of a series of software automatisms put in place to ensure that we can provide a good service level contract for our users.
“It is up to you as a node operator to verify that your node configuration is correct and that your node is reachable from the public internet. You must verify that the address your node gossips is reachable from the internet.“
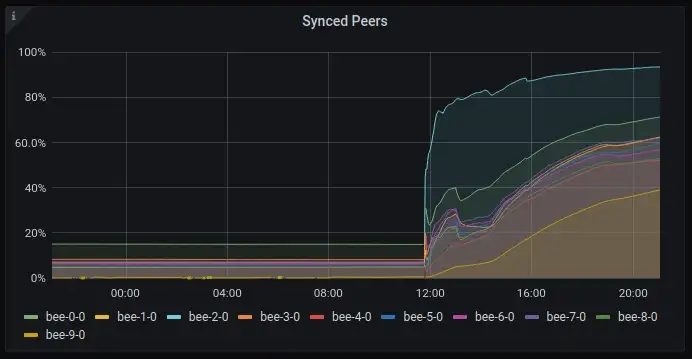
Prior to Bee v1.3.0, we could clearly see that the number of peers that were answering the newly added chainsync protocol was somewhere between 5–15%, as observed on the foundation’s clusters:


Now, looking at these numbers might be a bit misleading. This does not mean that only 5–15% were de-facto synced, but only that 5–15% were answering the messages. So it might be safer to assume that out of the entire network (still at the tens-of-thousands), only 5–15% actually updated their nodes and have a stable blockchain connection.
What’s next for the swarm?
The Bee team is working hard on collecting more data and iterating on more changes that would bring us more stability on the mainnet. In our next release cycle (Bee v1.4.0), we will be circumventing unreachable nodes from the core protocols: we’ve identified that a significant number of nodes are not publicly available and are not able to accept incoming connections as they are, e.g., behind NATs without port forwarding enabled, causing them to be ‘unreachable’ by many nodes in the network and giving rise to an unbalanced network topology.


Node connectivity data as of 05.11.2021
This is especially problematic for our Kademlia design, since it creates what we obscurely refer to as “concave neighbourhoods”, which are essentially asymmetric neighbourhoods that can never resolve their asymmetries due to participating nodes being unreachable. This causes all sorts of syncing and retrieval protocol failures that are difficult to get around without having relay nodes or enforcing a minimal configuration contract with other nodes. From Bee v1.4.0 onwards, if your node is unreachable, it will stop receiving messages on the core protocols.
As part of our changes in Bee v1.4.0 we’ve focused on this specific problem on several layers:
1. Detection — instating components that can do reachability detection and maintain the state of the node (and its peers). This is achieved directly within our p2p abstraction that provides a reachability service.
2. Visibility — making node reachability status (to display own reachability status and neighbouring peers’ reachability status) available for users and node operators. This is done through the topology endpoint in our Debug API.
3. Documentation — documenting how to resolve the problem (see the docs).
It is your responsibility as a node operator to verify that your node configuration is correct and that your node is reachable from public CIDRs. You must verify that the address that your node gossips is reachable from the internet.
While we are actively working on finding ways to be inclusive of unreachable nodes and allow them to participate in the network, it should be made clear we expect node operators to adhere to connectivity requirements and make their node reachable from public IP CIDRs.
Stay tuned for the next release cycle through our Twitter or Discord channel.
Discussions about Swarm can be found on Reddit.
All tech support and other channels have moved to Discord!
Please feel free to reach out via info@ethswarm.org
Join the newsletter! .
