

The Swarm research and development teams are thrilled to reveal that they are currently working on adding erasure coding (also referred to as erasure code or erasure encoding) to Swarm to increase the resilience of data stored on the Swarm network. The addition of erasure coding will provide a strong degree of protection so that data can always be downloaded, even in the event that some nodes or even entire neighbourhoods go offline. In this article, we will give an overview of the background and history of erasure coding, how it works, and the benefits it will bring to Swarm users.
Keeping Data Safe in a Chaotic World
The world is an inherently dangerous place for computers. No data are 100% safe from noise, interference, and distortion. We even need to worry about dangers as wild as cosmic rays! These can cause a bit to flip from a 0 to a 1 or vice versa or erase or add bits, and could potentially cause some very serious real-world problems, especially in situations where computers are relied on to keep people safe, such as airplane software, medical devices, train traffic controller software, etc. Of course, it can also cause problems in more mundane situations such as saving your term paper, computer game data or photos. But as you have probably noticed from using your computer and smart phone, your data aren’t constantly becoming corrupted, so how is this possible? The answer to this are data replication and error correction codes (of which erasure coding is one particular type).
Data Replication - A Good First Step
Data replication is the most straightforward and obvious method for keeping data safe. Simply put, copies of the data are made and saved in multiple different locations. Should one of the copies become corrupted or lost, a new copy can be made from one of the existing healthy copies. It is certainly a useful method for preserving data, although it also has some drawbacks. For one, it is expensive, as it requires multiple complete copies of data to be stored. Moreover, it does not inherently include a way to detect and correct errors. Even if you are able to store multiple copies of the data, you may run into trouble if some of the data becomes corrupted since when facing two alternative versions of the same data, we cannot easily tell which one is correct and which one was corrupted.
Error Correction Codes to the Rescue
In addition to replication, error correction codes are another powerful technique for keeping data safe. Error correction codes have been around for decades, and were pioneered by mathematician Richard Hamming in the 1950s with his eponymous Hamming codes. Hamming codes are based on the concept of the parity bit, which is an additional bit added to a string of binary code and is used to detect errors in the string. For each line of binary code, a single bit is added with a 0 or 1 value so that for the entire line of bits the sum of the 1s is always either odd or even (either may be chosen arbitrarily). If we choose that they should always be odd, we say it is odd parity, and even parity otherwise.
When sending data, we break the entire set of data into equal length bit strings to which we add one parity bit each. We then simply check each string of bits to check if they are all even or all odd, and if they are not, then we can know for certain that an error has occurred.
While this approach is excellent for detecting single bit errors, it has some limitations. Firstly, it cannot not tell us exactly where the error occurred, it can only tell us whether or not the bit string has an error somewhere in it. Secondly, if more than one error occurs, and the number of errors which have occurred is even, then we will not know that the error occurred at all since with two flips they will be back at their original odd or even state.
Rather than using a single parity bit for one bit string, Hamming codes combine multiple parity bits in such a way that the exact location of a bit flip can be pinpointed. However, it still has limitations when dealing with multiple bit errors.
While this approach to error correction may be somewhat primitive compared to the ones which followed it in later years, it is powerful, simple, and cheap (it only requires the addition of a small number of additional bits), and it is still being used even today.
Over the years many different forms of error correction have been developed. Generally speaking, they follow a similar broad pattern of breaking data into pieces and adding a small amount of additional “redundant” data to each piece of the original data which is structured in such a way that it allows for the detection and/or correction of errors.
Erasure Encoding - Next Level Error Correction
Erasure coding is a type of error correction code used to ensure that data are stored safely, even in the event that some pieces of the data become lost or corrupted. They are a sophisticated and powerful approach to data protection, and feature properties which make them extremely useful for distributed storage networks such as Swarm.
In the same way that Hamming codes rely on splitting data into bit strings and then adding additional parity bits which can help to protect the source data, erasure coding works by splitting the source data into “chunks” which are then encoded with additional data which can then help to protect the source data.
The seemingly magic advantage of erasure coding over Hamming code and other similar approaches is that even if some of the encoded chunks are lost, it is still possible to reconstruct 100% of the original source data, provided there are enough remaining chunks!
How it Works
With erasure coding the data are split into N chunks. (In Swarm, the splitting of data into chunks happens naturally via the DISC system which chops data up into 4KB fragments.) Then, a number of extra chunks (call it K) are added to these original N chunks, so we end up with N + K chunks. The data are then shuffled by the encoder across these N + K chunks, but in such a way that as long as you have at least N chunks of the N + K chunks of data (in other words, a loss of no more than K chunks), you can fully reconstruct the entire source data (hence the name “erasure” coding, as it can tolerate up to K erasures).
(The encoding and decoding processes involve some complex mathematics which will not be covered in this general introduction to erasure coding, but for a relatively pain-free introduction to them, check out this article, or for the more advanced reader, the erasure code Wikipedia page. Do note that in the linked article and many other articles on erasure coding, the values for N and K are defined somewhat differently than they are in this article).
Let’s take a look at an example of how this would work when storing an 8KB digital image.
For this example, let’s set our N value to 2 and our K value to 1. This means that we must take our 8KB image file and break it into 2 chunks (N), and add an additional 1 chunk (K). The source data are then shuffled across all 3 chunks along with the addition of the redundant data required for reconstructing the original data. Each chunk is encoded to be 1/2 (1/Nth) the size of the source data.
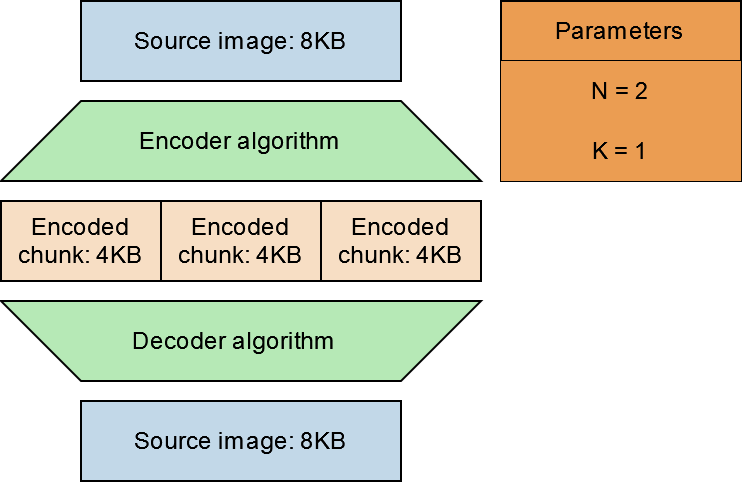
Now we store a total of 12KB of data and as long as we have any 2 out 3 encoded chunks, we can use those chunks to decode back to the original source file.
However, since we have only added an additional 1 (K) chunk, we can only tolerate the loss of a single chunk. If we wish to improve the protection of our data we can adjust our parameters.
We could instead for example change our K value to 4. In this case we are able to tolerate the loss 4 chunks rather than 1!
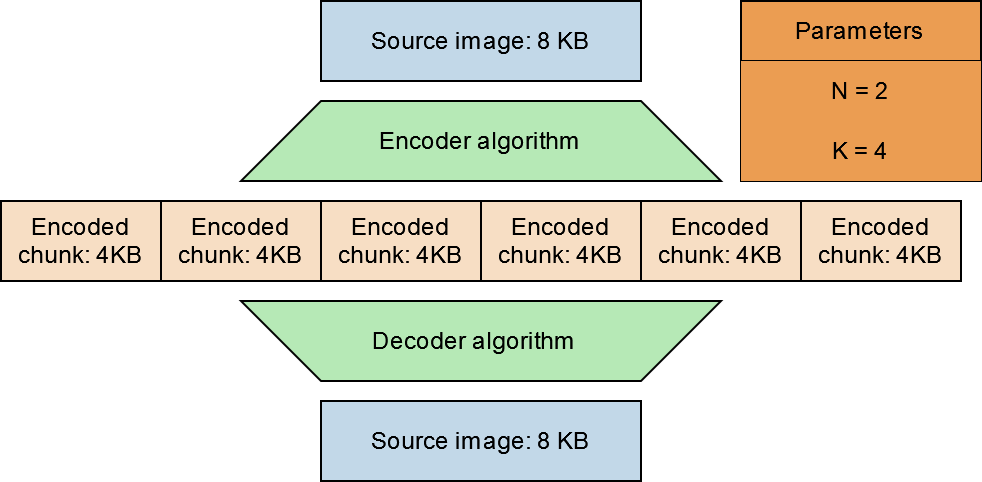
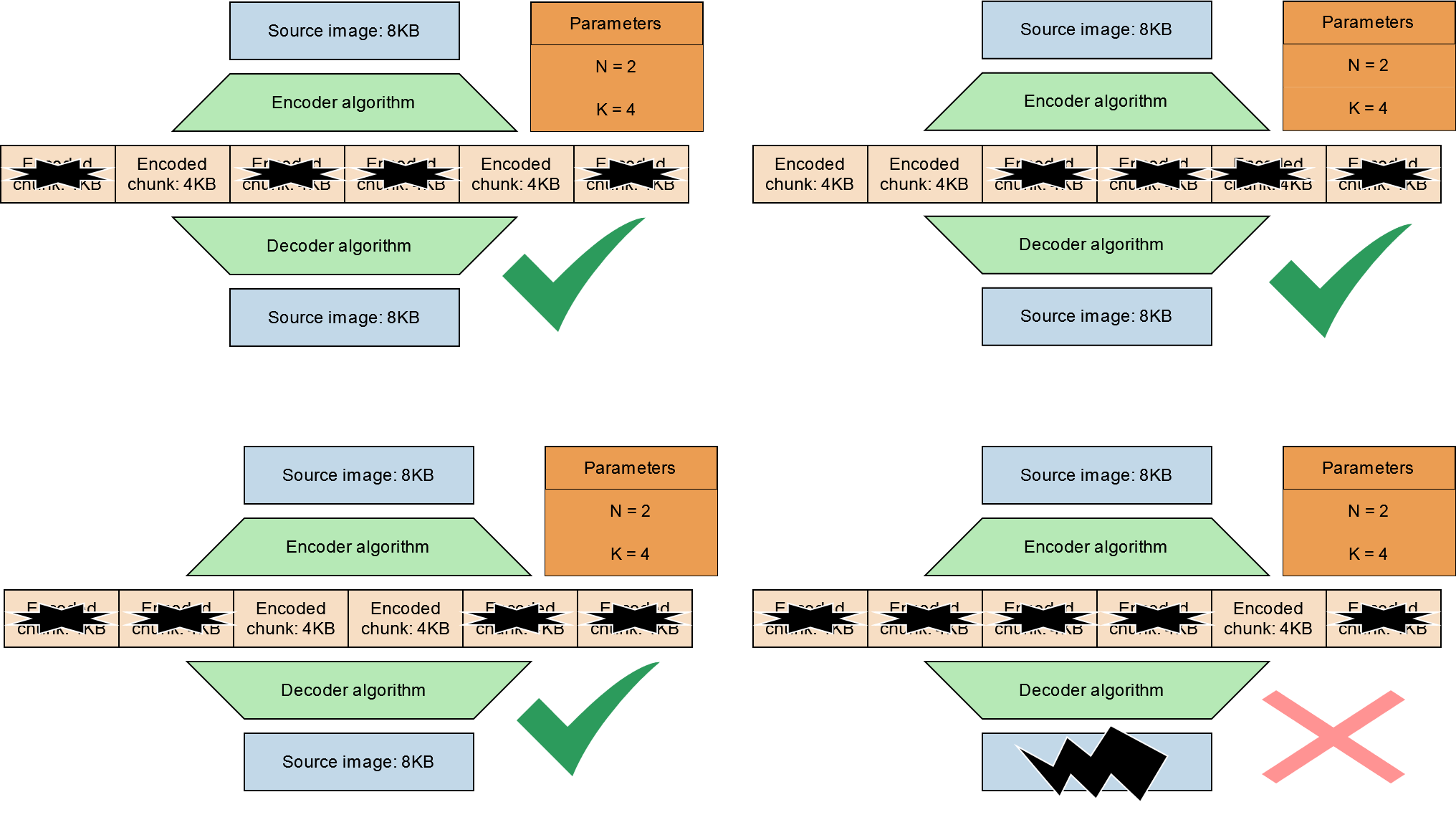
Note that it does not matter which chunks are erased as long as we still have at least 2 (N) chunks left. Up to 4 of any of the chunks can be erased and we are still able to reconstruct the original data. It is only when we have lost more than 4 (K) chunks that the original data is truly lost.
General Benefits of Erasure Coding
Cheaper and more secure
Erasure coding allows us to achieve the same or a greater degree of data protection than replication alone while requiring less disk space. Let’s take a look at an example to see exactly why. Let’s use an N=2, K=2 erasure coding scheme to protect an 8KB file:
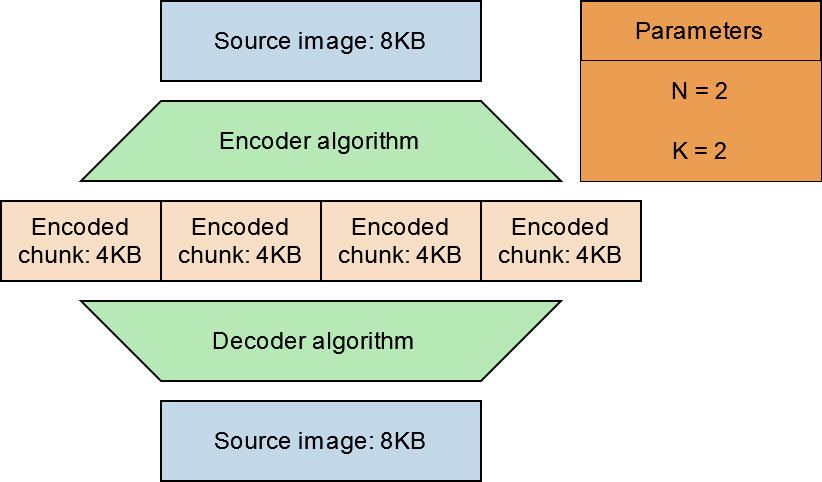
In this example the original file is 8KB, the space on disk after encoding is 16KB, and we can tolerate the erasure of up to two chunks. With replication, if we wish to use the same amount of disk space, we can only store two copies of the original data, and only a single erasure can be tolerated.
Can tolerate the loss of entire chunks of data unlike some error correction codes (Hamming codes)
With data protection schemes like Hamming code, errors can be detected within chunks of data; however, it cannot by itself protect against the loss of entire chunks. Erasure coding can actually tolerate the total erasure of a specified amount of chunks. Error correction codes such as Hamming code are still useful in many applications; however, they alone are not enough for use cases such as Swarm.
What does this mean for Swarm?
Erasure coding is the perfect data protection approach for Swarm’s unique design
Since Swarm’s DISC already splits files into chunks and spreads them out across a network of nodes, erasure coding is a great choice of data protection scheme. There is already a degree of replication built into Swarm, as each node within every neighbourhood keeps a copy of the chunks they are responsible for. However, there is still the risk that if an entire neighbourhood were to go offline, some of the original data may be lost. Erasure coding addresses this risk and provides a guarantee that even if an entire neighbourhood were to go offline, the original data would still be retrievable.
An extraordinary degree of data protection opens up Swarm to new use-cases
Overall, erasure coding is a cost effective way to significantly increase the durability of data being stored on Swarm. Its addition to Swarm marks a major step forward towards the goal of becoming a truly unstoppable decentralised storage network. Erasure coding function as an insurance against unexpected and unlikely events such as massive outages in data centers or deliberate attacks against certain neighbourhoods within the Swarm network. This additional degree of protection can make Swarm far more attractive for enterprise users and others who require an extraordinary degree of protection for their data.
Conclusion
The development of erasure coding on Swarm is already well underway. Our research and development teams are hard at work in their efforts to bring this new feature online. The research team is planning to soon release a technical paper outlining Swarm’s specific approach to using erasure coding. Stay tuned and follow us on socials to get the latest updates on these developments and others.
Sources
- https://en.wikipedia.org/wiki/Parity_bit
- Erasure Encoding for the Masses - https://towardsdatascience.com/erasure-coding-for-the-masses-2c23c74bf87e
- Error correction in general - https://www.youtube.com/watch?v=5sskbSvha9M
- Error correction continued: https://www.youtube.com/watch?v=bqtE6Q79PPs
- Reed solomon: https://www.youtube.com/watch?v=fBRMaEAFLE0
- Hamming codes Part 1: https://www.youtube.com/watch?v=X8jsijhllIA&pp=ygUNaGFtbWluZyBjb2Rlcw%3D%3D
- Hamming codes part 2 - implementation: https://www.youtube.com/watch?v=b3NxrZOu_CE&pp=ygUNaGFtbWluZyBjb2Rlcw%3D%3D
- Groups - https://www.youtube.com/watch?v=mH0oCDa74tE
- Fields - https://www.youtube.com/watch?v=bjp4nF8TW7s
Discussions about Swarm can be found on Reddit.
All tech support and other channels have moved to Discord!
Please feel free to reach out via info@ethswarm.org
Join the newsletter! .



